TripVVT: A Large-Scale Triplet Dataset and a Coarse-Mask Baseline for In-the-Wild Video Virtual Try-On
Abstract
Due to the scarcity of large-scale in-the-wild triplet data and the improper use of masks, the performance of video virtual try-on models remains limited. In this paper, we first introduce TripVVT-10K, the largest and most diverse in-the-wild triplet dataset to date, providing explicit video-level cross-garment supervision that existing video datasets lack. Built upon this resource, we develop TripVVT, a Diffusion Transformer-based framework that replaces fragile garment masks with a simple, stable human-mask prior, enabling reliable background preservation while remaining robust to real-world motion, occlusion, and cluttered scenes. To support comprehensive evaluation, we further establish TripVVT-Bench, a 100-case benchmark covering diverse garments, complex environments, and multi-person scenarios, with metrics spanning video quality, try-on fidelity, background consistency, and temporal coherence. Compared to state-of-the-art academic and commercial systems, TripVVT achieves superior video quality and garment fidelity while markedly improving generalization to challenging in-the-wild videos. We publicly release the dataset and benchmark, which we believe provide a solid foundation for advancing controllable, realistic, and temporally stable video virtual try-on.
Data Construction Pipeline
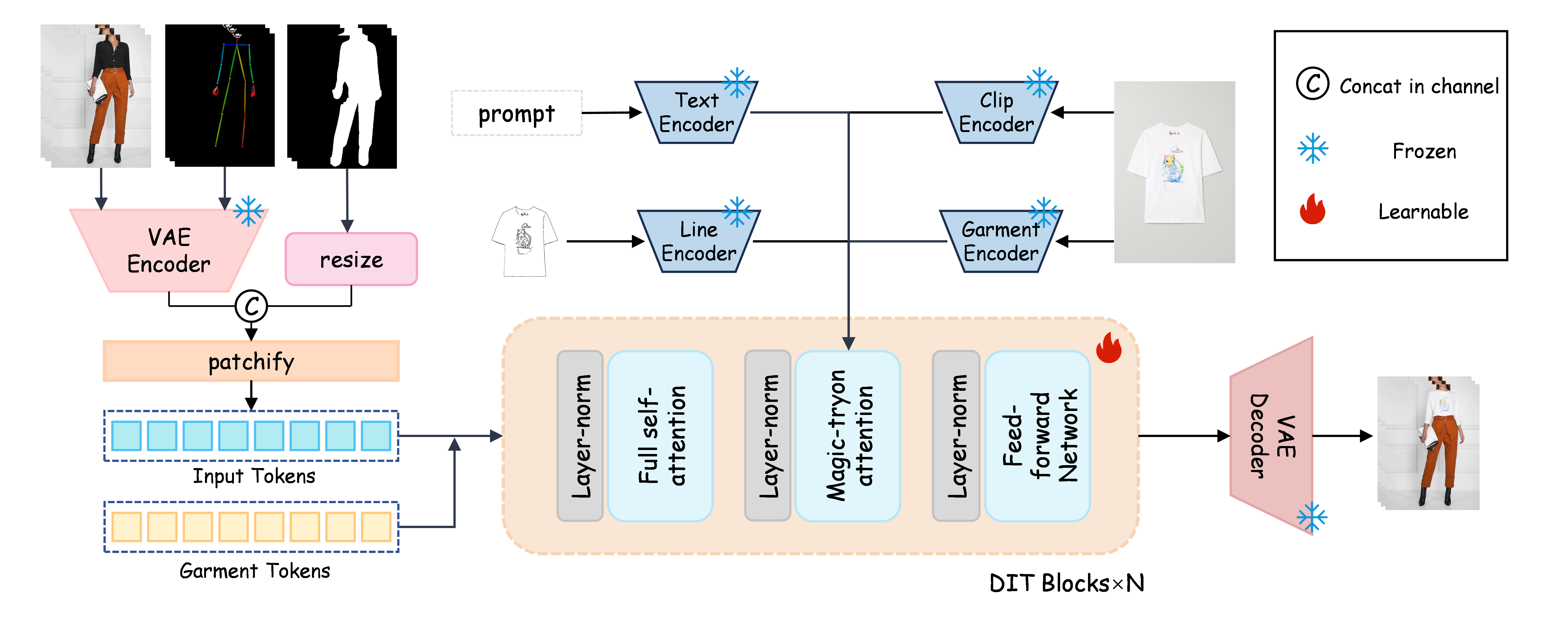
Model Architecture
TripVVT-10K Preview
Representative samples from TripVVT-10K.
Additional Qualitative Results
A compact set of extra qualitative examples from TripVVT-Bench and VIVID-S-Test.
TripVVT-Bench Additional Results
VIVID-S-Test Results
Failure Cases
Selected failure cases included for completeness and to illustrate challenging conditions that remain unresolved.